Purpose of this website
The project Observatory for Political Texts in European Democracies (OPTED; Horizon 2020 Grant agreement 951832) aims to design a European Research Infrastructure facilitating the large-scale computational analysis of political texts in Europe.
Work Package 5 focuses on national and supranational parliaments. We cover textual data on political speeches and debates as well as legislative texts produced in and by these key institutions of European democracy. On of the deliverables of WP5 was the organisation of the Data4Parliaments workshop in the European Parliament.
Easier access to existing text data collections as well as identifying the gaps in extant data avilability are among our key aims. Thus we have initially have assembled an inventory of available text data sources covering parliamentary activity. We identified the set of currently available sources - covering both primary archives and secondary data collections - by reviewing relevant academic literature, by scoping extant linguistic infrastructures (such as CLARIN), and by surveying the computational social science community via social media.
This website navigates prospective users and analysts through the inventory. It firstly provides a bird’s eye view om the coverage of existing primary archives and secondary data collections. THis shows where additional investements in text data collection are needed in particular. It secondly provides interactive tables through which users can filter and jump to already available sources along their specific research needs. If you use any of these sources, please cite them appropriately.
While we show all available sources we could uncover, we pay particular attention to what we call ‘ready-to-use’ data collections. We label existing data collections as ready-to-use if the respective source provides:
- clearly separated raw texts (such as individual speeches or unique legislative bills, e.g.)
- basic meta-data for individual texts (such as dates or names and parties of speakers, e.g.)
- data formats easily accessible (importable with less than 10 lines of code) in common open-source software environments offering broad text analysis tools (such as R and Python in particular)
Users interested in further detail than provided here may also review the full inventory, the respective codebook, or the technical reports specifying the major primary and secondary sources per country or supranational institution.
If a relevant data source or data collection is missing in your view, please do get in touch with the contributors below.
# RMD author: Christian Rauh (24.02.2021)
# Packages ####
library(tidyverse)
library(gsheet)
library(countrycode)
require(rworldmap)
require(mapproj)
require(viridis)
require(cowplot)
library(patchwork)
library(reactable)
library(ggplot2)
library(gsheet)
library(dplyr)
# Extract data from common google sheet ####
# Depends on formatting decisions there, cross check whenever the analysis is repeated!
# Latest: February 24 2021, 2 pm
# Speech Inventory
speeches <- as.data.frame(gsheet2tbl('https://docs.google.com/spreadsheets/d/1PAiJKhdBFcqQ-Ihu6KPPMdAAOnTG0dvM9LCtJ42w9fA/edit#gid=620510387'))
speeches <- speeches[,-1] # Drop first column, empty
names(speeches) <- speeches[5,] # the technical header
speeches <- speeches[6:nrow(speeches), ] # Remove non-technical header
speeches <- speeches %>%
select(-c(api, text.type, init.source, meta.vars, copyright.owner, comment, notes,
gender.av, leader.av, smd.av, codebook.av, database.id)) %>%
mutate_all(na_if, "-") %>%
mutate_all(na_if, "99") %>%
mutate_all(na_if, "N/A")
speeches$region <- speeches$region %>%
as.numeric() %>%
recode(`1` = "Central East Europe",
`2` = "Northern Europe",
`3` = "Southern Europe",
`4` = "Western Europe",
`5` = "Supranational",
`6` = "Other")
speeches$start.date <- speeches$start.date %>% as.numeric()
speeches$end.date <- speeches$end.date %>%
recode("up to date" = "2021") %>%
as.numeric()
speeches$texttypes <- ""
speeches$texttypes <- ifelse(speeches$plenary.speeches == 1, paste0(speeches$texttypes, "Plenary speeches"), speeches$texttypes)
speeches$texttypes <- ifelse(speeches$questions == 1, paste0(speeches$texttypes, ", Questions"), speeches$texttypes)
speeches$texttypes <- ifelse(speeches$interpellations == 1, paste0(speeches$texttypes, ", Interpellations"), speeches$texttypes)
speeches$texttypes <- str_remove(speeches$texttypes, "^, ")
speeches$texttypes <- ifelse(speeches$texttypes == "", "Other speech texts", speeches$texttypes)
table(speeches$texttypes)
speeches$iso3 <- countrycode(speeches$country, origin = "country.name", "iso3c")
speeches$ready <- as.logical(as.numeric(speeches$importable.metadata))
speeches$ready[is.na(speeches$ready)] <- F # What are these?
table(speeches$ready, useNA = "ifany")
# Law texts
laws <- as.data.frame(gsheet2tbl('https://docs.google.com/spreadsheets/d/1PAiJKhdBFcqQ-Ihu6KPPMdAAOnTG0dvM9LCtJ42w9fA/edit#gid=1192661106'))
names(laws) <- laws[5,] # the technical header
laws <- laws[6:nrow(laws), -1] # Remove non-technical header
write_rds(laws, "./data/Laws_20210330.rds")
laws <- laws %>%
select(-c(api, text.type, init.source, meta.vars, copyright.owner, comment, notes,
gender.av, leader.av, smd.av, codebook.av)) %>%
mutate_all(na_if, "-") %>%
mutate_all(na_if, "99") %>%
mutate_all(na_if, "N/A")
laws$region <- laws$region %>%
as.numeric() %>%
recode(`1` = "Central East Europe",
`2` = "Northern Europe",
`3` = "Southern Europe",
`4` = "Western Europe",
`5` = "Supranational",
`6` = "Other")
table(laws$region)
laws$start.date <- laws$start.date %>% as.numeric()
laws$end.date <- laws$end.date %>%
recode("up to date" = "2021") %>%
as.numeric()
laws$texttypes <- ""
laws$texttypes <- ifelse(laws$laws == 1, paste0(laws$texttypes, "Laws"), laws$texttypes)
laws$texttypes <- ifelse(laws$bills == 1, paste0(laws$texttypes, ", Bills"), laws$texttypes)
laws$texttypes <- ifelse(laws$amendments == 1, paste0(laws$texttypes, ", Amendments"), laws$texttypes)
laws$texttypes <- ifelse(!is.na(laws$other), paste0(laws$texttypes, ", Other legal text"), laws$texttypes)
laws$texttypes <- str_remove(laws$texttypes, "^, ")
table(laws$texttypes)
laws$iso3 <- countrycode(laws$country, origin = "country.name", "iso3c")
laws$ready <- as.logical(as.numeric(laws$importable.metadata))
laws$ready[is.na(laws$ready)] <- F # What are these?
table(laws$ready, useNA = "ifany")
# Store contemporary version locally
write_rds(speeches, "./data/Speeches_20210330.rds")
write_rds(laws, "./data/Laws_20210330.rds")A bird’s eye view on available parliamentary text data
Types of parliamentary texts
stypes <- speeches %>%
select(c(plenary.speeches, questions, interpellations)) %>%
mutate(across(everything(), as.numeric)) %>%
colSums(na.rm = T) %>%
data.frame() %>%
rename(count = 1) %>%
rownames_to_column() %>%
rename(type = rowname) %>%
mutate(type = str_replace(type, fixed("."), " ")) %>%
mutate(category = "Parliamentary speech")
ltypes <- laws %>%
select(c(laws, bills, amendments, other)) %>%
mutate(other = ifelse(is.na(other), 0, 1)) %>%
mutate(across(everything(), as.numeric)) %>%
colSums(na.rm = T) %>%
data.frame() %>%
rename(count = 1) %>%
rownames_to_column() %>%
rename(type = rowname) %>%
mutate(type = str_replace(type, fixed("."), "")) %>%
mutate(category = "Legislative texts")
types <- rbind(stypes, ltypes) %>%
mutate(category = factor(category, levels = c("Parliamentary speech", "Legislative texts")))
ggplot(types, aes(y= reorder(type,count), x=count)) +
geom_col(fill = "darkblue", alpha = .7)+
facet_wrap(.~category, nrow = 2, scales = "free_y")+
labs(y= "", x= "Number of data sources")+
theme_bw()+
theme(strip.text.x = element_text(face = "bold"),
axis.text.y = element_text(color = "black"))
With regard to speeches of and debates among MPs (and the government) the most frequently available text data type are full text transcriptions of plenary speeches. More specific debate types (such as parliamentary questions) are often nested within plenary debates (depending on the organisation of the respective parliament and/or its archive) and must be extracted separately. Dedicated data sources and/or collections for such speech types are only rarely available thus far.
With regard to legislative text, primarily the finally adopted laws are available (in many primary sources also limited to laws currently in force). Information on the intermediary stages of legislative decision-making - in particular with a view to bills and amendments - are much less frequently available thus far.
Geographical coverage
cat("\f")
rm(list=ls())
options(scipen = 999)
library(dplyr)
library(tidyverse)
library(ggplot2)
library(sf)
library(rnaturalearth)
library(rnaturalearthdata)
library(rgeos)
#adatok betoltese
table_speeches <- read.csv("table_speeches.csv", encoding = "UTF-8")
table_documents <- read.csv("table_documents.csv", encoding = "UTF-8")
#reelvans valtozok szelektalasa
table_speeches <- table_speeches[,c("country", "start.date", "end.date", "access.text")]
table_documents <- table_documents[,c("country", "start.date", "end.date", "access.text")]
#plot1:
#csak orszagok es csak, ha vannak hozza adatok
table_speeches <- subset(table_speeches, start.date != "N/A" & country %in% c("European Parliament",
"European Council",
"Council of the European Union",
"Council of Europe",
"European Commission",
"European Union") == F)
table_documents <- subset(table_documents, start.date != "N/A" & country %in% c("European Parliament",
"European Council",
"Council of the European Union",
"Council of Europe",
"European Commission",
"European Union") == F)
#numerikussa alakitom
table_speeches$start.date <- as.numeric(table_speeches$start.date)
table_speeches$end.date <- as.numeric(table_speeches$end.date)
table_documents$start.date <- as.numeric(table_documents$start.date)
table_documents$end.date <- as.numeric(table_documents$end.date)
#funkcio a lefedett evekhez
years_covered <- function(start_vec, end_vec){
#ures vector
vec <- c()
#a kezdet es a start minden ertek parjabol csinalok egy sorozatot
for (i in 1:length(start_vec)){
#mindegyiket az ures vectorba helyezem
vec <- c(vec, seq(from = start_vec[i], to = end_vec[i], by = 1))
}
#visszaadom az egyedi ertekek szamat
return(length(unique(vec)))
}
#megnezem a lefedett evek szamat orszagonkent
table1 <- summarise(group_by(table_speeches, country), years = years_covered(start.date, end.date))
table2 <- summarise(group_by(table_documents, country), years = years_covered(start.date, end.date))
#load in world map
world1 <- ne_countries(scale = "medium", returnclass = "sf")
world2 <- ne_countries(scale = "medium", returnclass = "sf")
#join the data:
names(table1)[1] <- "sovereignt"
names(table2)[1] <- "sovereignt"
world1 <- left_join(world1, table1, by = "sovereignt")
world2 <- left_join(world2, table2, by = "sovereignt")
world1$type <- "Speeches"
world2$type <- "Documents"
world <- rbind(world1, world2)
#plot our results
plot1 <- ggplot(world) +
geom_sf(aes(fill = years)) +
scale_fill_gradient(low = "yellow", high = "red")+
coord_sf(xlim = c(-25,35), ylim = c(34,70), expand = FALSE)+
facet_wrap(~type)+
theme(axis.text.x=element_blank(),
axis.text.y=element_blank(),axis.ticks=element_blank(),
axis.title.x=element_blank(),
axis.title.y=element_blank())
plot1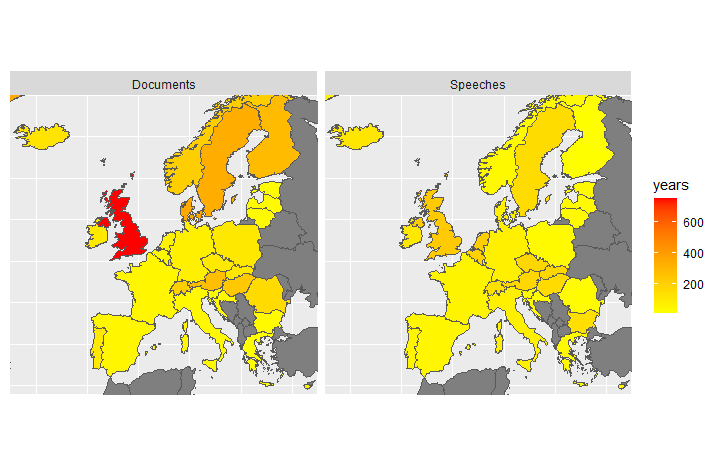
Comparing the left and the right panel of the plot one immediately sees that many primary sources of parliamentary text data have not been transferred to ‘ready-to-use’ data sets that would be easily amenable to automated text analysis. Especially where comparatively well-structured primary sources exist, additional data collection efforts appear to be a low hanging fruit.
We also see that the availability of ‘ready-to-use’ data is particularly scant for legislative texts. Given that negotiating and fixing collectively binding rules are a key purpose of parliaments in democratic states, we thus far can hardly exploit the power of text-as-data aproaches for these processes.
We also see striking geographical imbalances: Some countries such as Germany and France are covered by various sources already, whereas systematic data on Central and Eastern European countries is much more scarce.
In adddition, there are no ‘ready-to-use’ text data collections combining multiple countries, with ParlSpeech being the only exception.
# Check for multi-country, ready-to-use
lsourc <- laws %>% select(source.name, country, ready)
lsourc$dupl <- duplicated(lsourc) # Duplicates: same source, same country, but proabaly different text types
lsourc <- lsourc %>% filter(!dupl) %>%
group_by(source.name) %>%
summarise(countries = paste(country, collapse =", "),
ready = mean(ready, na.rm =T)) %>%
mutate(c.cover = str_count(countries, ",")) %>%
arrange(desc(c.cover))
# lsourc$multi <- ifelse(lsourc$ready == 1 & lsourc$c.cover > 0, T, F)
# lsourc$source.name[lsourc$multi]
ssourc <- speeches %>% select(source.name, country, ready)
ssourc$dupl <- duplicated(ssourc) # Duplicates: same source, same country, but proabaly different text types
ssourc <- ssourc %>% filter(!dupl) %>%
group_by(source.name) %>%
summarise(countries = paste(country, collapse =", "),
ready = mean(ready, na.rm =T)) %>%
mutate(c.cover = str_count(countries, ",")) %>%
arrange(desc(c.cover))
# ssourc$multi <- ifelse(ssourc$ready == 1 & ssourc$c.cover > 0, T, F)
# ssourc$source.name[ssourc$multi]
# There are none, except ParlSpeech ...
Temporal coverage of ‘ready-to-use’ sources
rm(table1, table2, world, world1, world2, years_covered)
#plot2
names(table_documents) <- c("country", "start", "end", "access")
names(table_speeches) <- c("country", "start", "end", "access")
#tablak elokeszitese
table_range <- function(table){
df <- data.frame()
for (i in 1:nrow(table)) {
c1 <- table[i,]
c1$date <- c1$start
c2 <- table[i,]
c2$date <- c2$end
current <- rbind(c1, c2)
df <- rbind(df, current)
}
return(df)
}
table1 <- table_range(table_speeches)
table2 <- table_range(table_documents)
table1$type = "Speeches"
table2$type = "Documents"
table <- rbind(table1, table2)
table[which(table$access == 0), "access"] <- "Web scraping needed"
table[which(table$access == 1), "access"] <- "Available in a single dataset"
table[which(table$access == 2), "access"] <- "Dataset with links to full textfiles"
table[which(table$access == 88), "access"] <- "Available upon request"
table[which(table$access == 99), "access"] <- "Not accessible"
unique(table$access)
#plotting
levels(table$access)
table$access <- factor(table$access, levels = c("Available in a single dataset",
"Dataset with links to full textfiles",
"Web scraping needed",
"Available upon request",
"Not accessible"))
table <- arrange(table, desc(access))
plot2 <- ggplot(table, aes(x = date, y = country)) +
theme(axis.title.x = element_blank(),
axis.title.y = element_blank())+
geom_linerange(aes(xmin = start, xmax = end, linewidth = 4, color = access))+
facet_wrap(~type, scales = "free")+
guides(colour = guide_legend(override.aes = list(linewidth=4)))+
guides(linewidth = "none")+
labs(color = "Text accessability")+ scale_color_manual(values=c("darkgreen", "lightgreen", "yellow", "orange", "red"))
plot2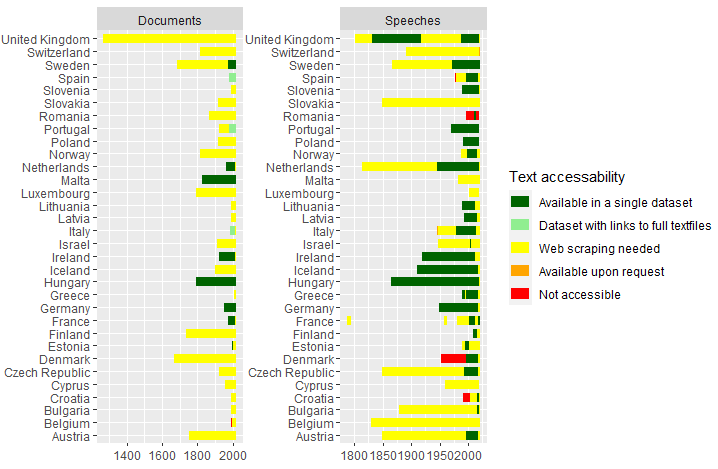
The temporal perspective reinforces imbalances already seen above. Especially countries from Western (and partially Northern) Europe are overrepresented in terms of data availability. For many Eastern European States, with the exception of Hungary, text data on parliamentary debates is limited mostly to the last decade. Legislative text data is lacking for the majority of European democracies where the supranational institutions provide a positive exception.
Find your data source: Parliamentary speeches
sout <- speeches %>%
select(c(country, source.name, primary, texttypes, start.date, end.date, coverage, ready, source.link)) %>%
mutate(country.report = "https://www.dropbox.com/sh/xxm0z74h6i0miam/AAADLToevTR-XTKaJ9rF2q5_a?dl=0")
sout$coverage[is.na(sout$coverage)] <- 0 # Cross-check
sout$coverage <- ifelse(sout$coverage == 1, T, F)
sout$primary <- ifelse(sout$primary == 1, "Primary", "Secondary")
reactable(sout[, -c(2,10)], defaultSorted = "country",
pagination = F,
bordered = T,
highlight = TRUE,
wrap = F,
resizable = TRUE,
height = 300,
showSortIcon = T,
filterable = TRUE,
minRows = 0,
columns = list(
country = colDef(name = "Country"),
texttypes = colDef(name = "Text types"),
primary = colDef(name = "Archive type", align = "center"),
# texttypes = colDef(name = "Text types"),
start.date = colDef(name = "Start Year", align = "center"),
end.date = colDef(name = "End Year", align = "center"),
coverage = colDef(name = "Full coverage?", align = "center",
cell = function(value) {
# Render as ✘ or ✓
if (value == FALSE) "\u2718" else "\u2713"
}),
ready = colDef(name = "Ready to use?", align = "center",
cell = function(value) {
# Render as ✘ or ✓
if (value == FALSE) "\u2718" else "\u2713"
}),
source.link = colDef(cell = function(value) {
# Render as a link
htmltools::tags$a(href = value, target = "_blank", as.character("Click"))
}, name = "Access source", align = "center")
# country.report = colDef(cell = function(value) {
# # Render as a link
# htmltools::tags$a(href = value, target = "_blank", as.character("Link"))
# }, name = "Country Report")
),
details = function(index) {
htmltools::div(
"Source name: ",
htmltools::tags$pre(paste(capture.output(sout$source.name[index]), collapse = "\n")),
"Detailed country report:",
htmltools::tags$pre(paste(capture.output(sout$country.report[index])), collapse = "\n"))
}
)
Find your data source: Legislative texts
lout <- laws %>%
select(c(country, source.name, primary, texttypes, start.date, end.date, coverage, ready, source.link)) %>%
mutate(country.report = "https://www.dropbox.com/sh/xxm0z74h6i0miam/AAADLToevTR-XTKaJ9rF2q5_a?dl=0")
lout$coverage[is.na(lout$coverage)] <- 0 # Cross-check
lout$coverage <- ifelse(lout$coverage == 1, T, F)
lout$primary <- ifelse(lout$primary == 1, "Primary", "Secondary")
reactable(lout[, -c(2,10)], defaultSorted = "country",
pagination = F,
bordered = T,
highlight = TRUE,
wrap = F,
resizable = TRUE,
height = 300,
showSortIcon = T,
filterable = TRUE,
minRows = 0,
columns = list(
country = colDef(name = "Country"),
texttypes = colDef(name = "Text types"),
primary = colDef(name = "Archive type", align = "center"),
# texttypes = colDef(name = "Text types"),
start.date = colDef(name = "Start Year", align = "center"),
end.date = colDef(name = "End Year", align = "center"),
coverage = colDef(name = "Full coverage?", align = "center",
cell = function(value) {
# Render as ✘ or ✓
if (value == FALSE) "\u2718" else "\u2713"
}),
ready = colDef(name = "Ready to use?", align = "center",
cell = function(value) {
# Render as ✘ or ✓
if (value == FALSE) "\u2718" else "\u2713"
}),
source.link = colDef(cell = function(value) {
# Render as a link
htmltools::tags$a(href = value, target = "_blank", as.character("Click"))
}, name = "Access source", align = "center")
# country.report = colDef(cell = function(value) {
# # Render as a link
# htmltools::tags$a(href = value, target = "_blank", as.character("Link"))
# }, name = "Country Report")
),
details = function(index) {
htmltools::div(
"Source name: ",
htmltools::tags$pre(paste(capture.output(lout$source.name[index]), collapse = "\n")),
"Detailed country report:",
htmltools::tags$pre(paste(capture.output(lout$country.report[index])), collapse = "\n"))
}
)
Contributors - the WP5 team
University of Cologne
- Sven-Oliver Proksch
- Jan Schwalbach
- Alexander Dalheimer
